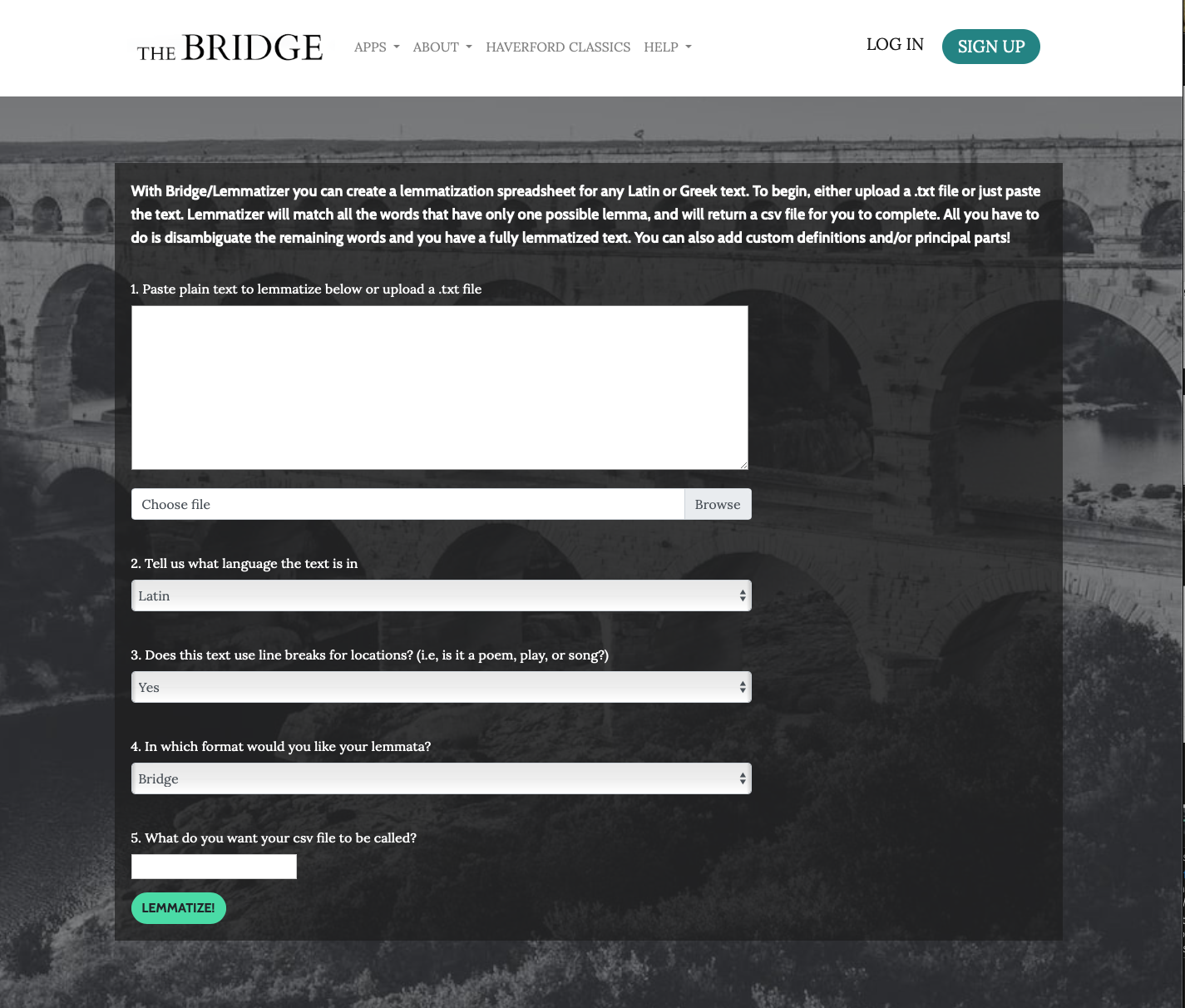
Lemmatization is the association of words in a text with their dictionary headwords. The hybrid mode of lemmatization, which automates the identification of unambiguous words while leaving for human editors decisions about ambigious words, has produced most of the highly accurate text data in The Bridge. Bridge/Lemmatizer offers a way to create accurate vocabulary lists for any Ancient Greek or Latin text that can grow and evolve alongside your needs.

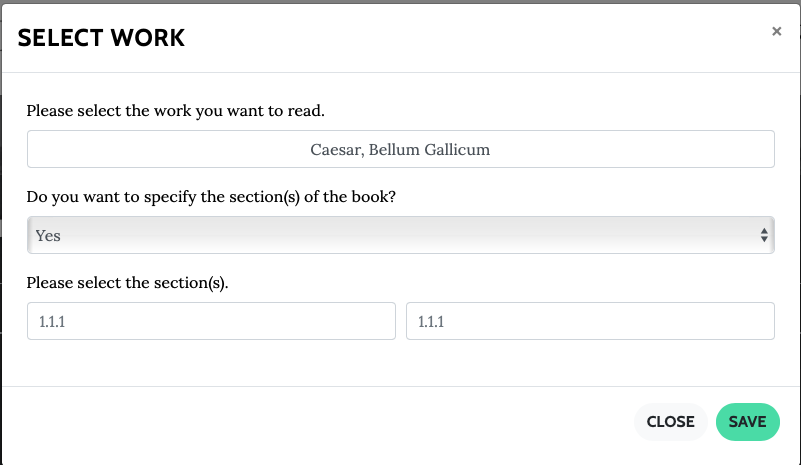
To begin, either upload a .txt file or just paste the text into the window. (2) Select the Language. (3) Indicate whether the text uses line breaks to generate location (e.g., a poem); if not, locations should be enclosed within square brackets (e.g., [14.1.1]); (4) Select the format of the lemmatization parses (Bridge or Morpheus); and (5) name your file.
Lemmatizer will match all the words that have only one possible lemma, and will return a csv file for you to complete. All you have to do is disambiguate the remaining words and you have a fully lemmatized text. You can also add custom definitions and/or principal parts!
You can work on your lemmatization file in any spreadsheet program (like Excel, Sheets, etc.). Once you’ve imported it, you’ll see something like this.
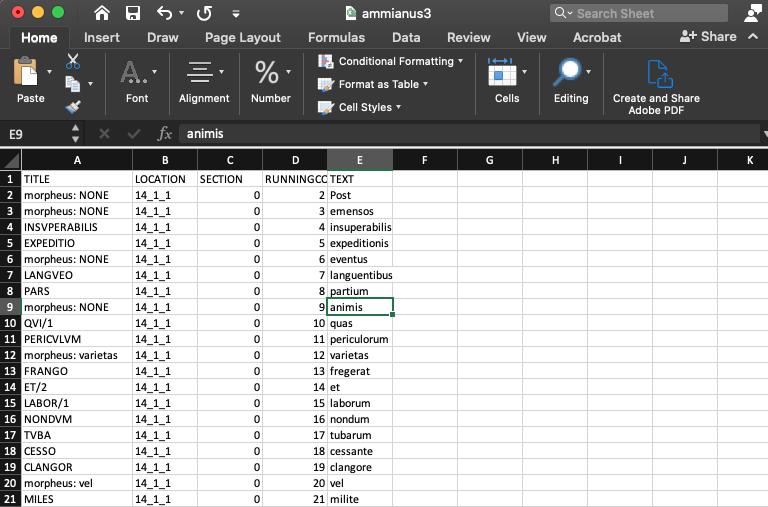
In the sample file, every unambiguous word has been lemmatized (e.g., INSVPERABILIS, EXPEDITIO, LANGVEO, etc.), while those that are ambiguous have been tagged (“morpheus: NONE — i.e., the lemmatizer has not been able to identify a unique lemma for the word).
For additional guidance on importing .csv files into spreadsheets, importing dictionaries, and lemmatizing, see the Quickstart Guide to Lemmatizing.